
[bibshow file=library.bib key_format=cite]
[wpcol_1half id="" class="" style=""]
Different kind of learning
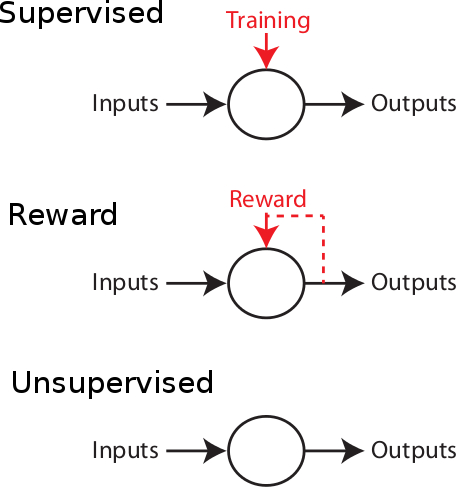
Supervised learning: the more commonly used approach in artificial intelligence, is a machine learning framework in which where an error signal (or a reward signal, if we speak about reward learning) is present to instruct the system what should be learned, and when. Positive actions and/or behaviours and/or patterns produced in front of a set of learning stimuli are stored in order to produce a correct response to a new set of stimuli, by generalization. The system learns associations based on a list of training examples under the form 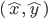 , where
, where 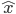 is typically a vector of input variables fed to the system, and
is typically a vector of input variables fed to the system, and 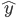 the desired output of the system: it can be a continuous value or a class if the goal is to classify the inputs. There are several pieces of evidence that supervised learning exists in the brain, where reward signals may take the form of neurotransmitter or neuromodulator release. Each time a positive action is produced by the organism, neurotransmitters may validate or consolidate the synapses that lead to particular behaviours useful for the organism. Direct and indirect pieces of evidence are numerous to show how for example noradrenaline, dopamine and acetylcholine can influence the behaviour and therefore be a key factor in memory retention.
the desired output of the system: it can be a continuous value or a class if the goal is to classify the inputs. There are several pieces of evidence that supervised learning exists in the brain, where reward signals may take the form of neurotransmitter or neuromodulator release. Each time a positive action is produced by the organism, neurotransmitters may validate or consolidate the synapses that lead to particular behaviours useful for the organism. Direct and indirect pieces of evidence are numerous to show how for example noradrenaline, dopamine and acetylcholine can influence the behaviour and therefore be a key factor in memory retention.
Unsupervised learning: the ability of the brain to self-organize its connections within networks without any teacher or reward signal. This is the kind of learning which is thought to occur in all the primary sensory areas. In the visual cortex, for example, neurons are organized in functional maps of orientation preference, direction preference, ocular dominance and so on. No feedback signal is present to tell the brain what should be learned in the input signals. This spontaneous organization occurs even before any visual experience, and therefore the neurons spontaneously organize themselves into an efficient basis in which inputs can be easily decomposed and processed. Because of the presence of ongoing patterns of activity at a prenatal stage, numerous work in the vertebrate brain has shown that the travelling waves due ``dark discharge" in the retina are sufficient to influence laminar segregation and ON & OFF specialization in the thalamus. The orientation columns in V1 are considered as crucial to allow fast and robust image segmentation, binding, and so on. This plasticity is mainly activity-driven: close-by neurons tend to receive correlated inputs, due to the retinotopic organization, and therefore a particular mechanism should consolidate the fact that receiving correlated activity implies a similar coding scheme, or common inputs.
[/wpcol_1half]
[wpcol_1half_end id="" class="" style=""]
[/wpcol_1half_end]
Hebbian Learning
Most of the work on unsupervised learning in the brain has been based, since more than fifty years, on a well-known postulate made by [bibcite key=Hebb1949]:
[quote]When an axon of cell A is near enough to excite cell B and repeatedly or persistently takes part in firing it, some growth process or metabolic change takes place in one or both cells such that A's efficiency, as one of the cells firing B, is increased[/quote]
Here can be found the basis of causal associations in the unsupervised learning framework. This postulate is a local and associative rule, meaning that causal activities between two connected neurons should lead to a synaptic reinforcement between them. Neurons do not need to integrate activity from other neurons: the evolution of the synapses between them results only from their own activities (``homosynaptic" plasticity, according to the terminology of Eccles). If 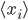 and
and 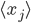 are the averaged firing rates of two neurons
are the averaged firing rates of two neurons  and
and  , then if
, then if 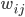 is a synapse between and , we have according to Hebb's postulate:
is a synapse between and , we have according to Hebb's postulate:
\begin{equation}
\frac{dw_{ij}}{dt} = F(w_{ij}, \langle x_i \rangle, \langle x_j \rangle)
\end{equation}
with 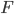 being an unknown function. The rule is cooperative, the postulate stating that both pre- and post-synaptic neurons have to be active together in order to trigger synaptic modifications. Therefore, in the simplest form, the rule is used as:
being an unknown function. The rule is cooperative, the postulate stating that both pre- and post-synaptic neurons have to be active together in order to trigger synaptic modifications. Therefore, in the simplest form, the rule is used as:
\begin{equation}
\frac{d w_{ij}}{dt} = \eta \langle x_i\rangle \langle x_j\rangle
\end{equation}
where 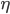 is a constant to scale the evolution of the weights. From a biological point of view, since synapses are well isolated and protected by glia cells, the synaptic clefts are rather isolated areas. Therefore, if we ignore the possible role of glia cells in memory consolidation, this Hebbian hypothesis that synaptic efficiency can be regulated only by pre-post electrical activity is tempting.
is a constant to scale the evolution of the weights. From a biological point of view, since synapses are well isolated and protected by glia cells, the synaptic clefts are rather isolated areas. Therefore, if we ignore the possible role of glia cells in memory consolidation, this Hebbian hypothesis that synaptic efficiency can be regulated only by pre-post electrical activity is tempting.